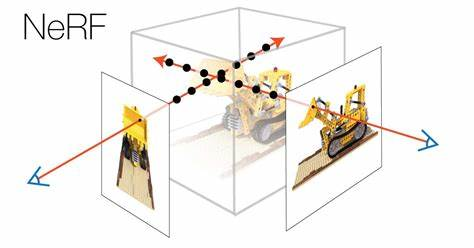
NoPe-NeRF: Optimising Neural Radiance Field with No Pose Prior
摘要
训练一个没有预先计算相机姿态的神经辐射场(NeRF)是具有挑战性的。最近在这个方向上的进展展示了在前向场景中联合优化NeRF和相机姿态的可能性。然而,这些方法在摄像机有剧烈移动时仍然面临困难。为了解决这个具有挑战性的问题,我们引入了无畸变单目深度先验。这些先验是通过在训练过程中校正尺度和平移参数生成的,然后我们可以用它们来约束相邻帧之间的相对姿态。这个约束是通过我们提出的新型损失函数来实现的。对于真实世界室内和室外场景的实验表明,我们的方法可以处理具有挑战性的相机轨迹,并在新视角渲染质量和姿态估计准确性方面优于现有方法。我们的项目页面是https://nope-nerf.active.vision。
1. Introduction
略
2 相关工作
2.1 新视角合成
早期新视角合成使用像素之间的插值。后来则通常使用 3D 重建渲染图像。最近最流行的场景表示方法则为 NeRF. 而相关的 NeRF 及其优化应用方法都需要使用 SfM 预训练来获得训练集的相机位姿。
2.2 位姿优化 NeRF
近期的一个研究热点为简化或消除相机位姿参数的预处理这一步骤。一类方法使用 SLAM 风格。另一类方法直接优化相机姿态与 NeRF 模型 (unposed-NeRF).
iNeRF 的研究表明可以使用重建的 NeRF 模型估计图像姿态。GNeRF 将生成对抗网络和 NeRF 结合以估计相机姿态,但需要已知姿态采样分布。
NeRFmm 提出同时优化相机的内参和外参。BARF 提出了一种位置编码策略来联合优化相机姿态与 NeRF. SC-NeRF 进一步参数化相机的失真,采用几何损失对射线进行规范化。GARF 表明使用高斯-MLP 使得联合姿态和场景优化更加容易和准确。SiNeRF 使用 SIREN 层和一种新采样策略来缓解 NeRFmm 中的联合优化次优性问题。虽然在像 LLFF 这样的前向数据集上显示了好结果,但在处理具有大相机运动和复杂相机轨迹时仍然面临困难。我们通过将mono-depth 图与相机参数和 NeRF 联合优化紧密结合来解决问题。
注解:先前工作对位姿同时优化的研究:
1. 最简单的同时优化想法:用 BP 同时优化位姿,但容易陷入次优解
2. 位置编码虽然可以加速重建,但也容易导致次优解
3. BARF提出使用经典图像对齐同时优化位姿和模型
NeRFmm提出通过光度损失同时优化位姿和模型
关于几何-辐射模糊性
NeRF++ 提出来了这一点。NeRF 本身高频输入坐标+相对低频后输入位姿可以很好地避免几何-辐射模糊性。
3. 方法
本文将解决:在无位姿信息的 NeRF 训练中处理大相机运动的挑战。
给定图像、相机内参和单目深度估计,可以同时恢复相机姿态并优化 NeRF. 假设相机内参在图像元信息中可用,可以运行 DPT 获取单目深度估计。
训练过程中,我们对相机姿态和每个单目深度图的畸变参数进行联合优化。畸变参数通过最小化单目深度图与从 NeRF 渲染的深度图之间的差异来进行监督,后者是多视图一致的。反过来,无畸变的深度图有效缓解了形状-辐射二义性,简化了 NeRF 和相机姿态的训练。
具体而言,无畸变的深度图实现了两个约束。通过相邻图像之间的相对姿态来限制全局姿态估计。通过从无畸变深度图反投影的两个点云间的倒角距离来实现。此外还通过将无畸变深度视为表面,使用基于表面的光度一致性对相对姿态估计规范化。
3.1 NeRF
NeRF 将场景表示为映射神经网络(具体见 NeRF 论文)。给定 $N$ 张图片 $I_1,…,I_n$ 和相应位姿 $\pi_1,…,\pi_n$,这个 NeRF 网络可以通过最小化光度误差作为 loss 来优化($L_{rgb}=\sum_i^N||I_i-\hat I_i||_2^2$).
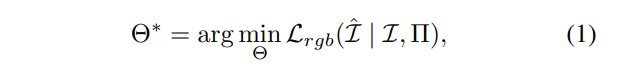
其中 $ L_{rgb} = \sum_i^N ||Ii − \hat Ii||_2^2$,$\hat I$ 是
(复述 NeRF)
3.2 对位姿和 NeRF 的联合优化
先前有研究表明有可能通过在体积渲染过程中最小化光度误差来同时估计相机参数和 NeRF。
关键在于将相机的光线投射化为相机参数 $\Pi$。此时相机射线 $r$ 作为相机位姿的函数。数学上这种联合优化可以表示为: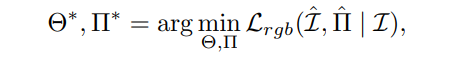
相机参数 $\Pi$ 包括相机内参、姿态和镜头畸变等。但在 Nope-NeRF 中,我们只考虑相机姿态。例如帧 $L_i$ 的姿态是一个变换 $T_i=[R_i|t_i]$(齐次坐标下旋转矩阵和位移向量的增广阵)
3.3 单目深度估计去畸变
使用现成的 DPT 做单目深度,可以从输入图像生成单目深度图序列 $D=\{D_i|i=0,…,N-1\}$. 单目深度图并不与多视图一致,因此我们的目标是恢复一系列多视图一致的深度图。
具体来说,对每一个单目深度图,考虑两个线性变换参数,得到所有帧的变换参数序列 $\alpha_i,\beta_i$,分别表示缩放因子和位移因子。通过 NeRF 的多视图一致性约束,可以恢复 $D_i$ 的多视图一致深度图。
通过同时优化 $\alpha_i$,$\beta_i$ 以及 NeRF 模型来进行联合优化。这种联合优化主要通过无畸变深度图 $D_i^*$ 和 NeRF 渲染的深度图 $\hat D_i$ 之间的一致性来实现。深度损失函数如下:
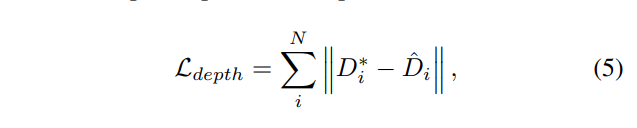
其中
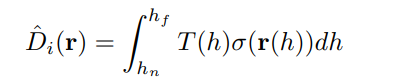
表示 NeRF 经过体渲染得到的深度图。
注意 NeRF 和单目深度图都通过公式(5)优化. 单目深度为 NeRF 提供了几何先验,减少了形状-辐射二义性。另一方面,NeRF 提供了多视图一致性,因此可以恢复一组多视图一致的深度图用于姿态估计。
3.4 相对姿态约束
先前的工作独立优化每个相机姿态,导致对错误姿态的图像进行过拟合。对帧间不正确的相对姿态进行惩罚可以规范联合优化,使得在复杂的相机轨迹下平滑收敛。因此我们提出两个约束相对姿态的损失函数。
- 点云
用相机内参数将无畸变深度图 $D^$ 反投影为点云 $P^$,通过最消化点云损失来优化相对姿态:
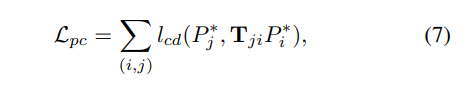
其中 $T_{ji}=T_jT_i^{-1}$,表示从点云 $P_i^$ 通过 $T$ 变换到的估计点云 $P_j^$ ,
$l_{cd}$ 表示倒角距离。
- 表面光度损失
$L_{pc}$ 在 3D-3D 匹配方面进行了监督,但给予表面的广度误差可以减轻不正确的匹配。在光度一致性假设下,该光度惩罚相关像素外观的差异。
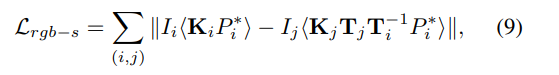
其中乘法为取样操作。$K_i$ 是第 $i$ 个相机的投影矩阵。
3.5 完整的训练 pipeline
我们的整个 loss 可以表示为:
$\lambda_i$ 为超参数,权重。
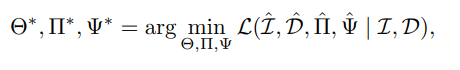
最后返回 NeRF 的参数 $\Theta$,相机位姿 $\Pi$ 和畸变参数 $\Psi$.
4. 实验
4.1 本文实验方法
数据集:Tanks and Temples 和 ScanNet.
Tanks Temples 包含 8 个场景用于评估姿态和新视角合成质量。图像下采样到 960x540,对 family 场景采样 200 张图像,奇数帧用于训练集,偶数帧用于新视角合成测试。
ScanNet 中,我们采用 4 个场景用于评估姿态准确性、深度准确性和新视角合成质量。对每个场景使用 80-100 个连续图像,使用其中 1/8 用于新视角合成。评估使用 ScanNet 提供的深度图和姿态作为 ground truth. 所有 ScanNet 图都下采样到 648x484,预处理时裁剪带有黑边的图像。
评估指标:对新视角合成,使用峰值信噪比(PSNR)、结构相似性指数(SSIM)和学习感知图像块相似性(LPIPS);对姿态评估,使用标准视觉里程计指标,包括绝对轨迹误差和相对姿态误差。使用 ATE 衡量估计的相机位置与 groundtruth 之间的差异。使用 RPE 衡量成对图像之间的相对姿态误差,包括相对旋转误差(RPEr)和相对平移误差(RPETA)。使用标准的深度估计指标。遵循 Zhou 等人的方法匹配渲染深度图和 ground truth 深度图的中值。
details:
- 修改了 NeRF 结构,用 Softplus 替换 ReLU 激活函数。意义不明,但可能实验结果更好,总之没有说原因。
- 预定义范围 (0.1, 10) 内在每条射线上均匀采样 128 个点。使用 2 个单独的 Adam 优化器优化 NeRF 和其它参数。NeRF 初始学习率 0.001,姿态和畸变初始学习率 0.0005…
复现
代码地址:
问题
单目深度估计的畸变,会出现非线性畸变吗?
这方面好像没有做实验,只是提了一嘴,目前我也并不知道单目深度估计除了尺度与偏移的畸变还有哪些原因会导致其他不同性质的畸变。
2-stage 是怎么做的?
NoPe-NeRF 的方法与 COLMAP 的两步法不一致,是联合优化模型与位姿的。但文中为了对比其与传统 NeRF 的性能,将 NoPe-NeRF 网络改为 2-staged,即先单独估计位姿,再训练出模型,这与联合优化是完全相悖的,这种 2-stage 方法非常奇怪,作者也没有给出具体的网络方法,莫名其妙。
大相机运动?
文中并没有直接给出能证明大相机运动优于其他 NeRF 方法的实验结果,却直接把 “能处理大相机运动” 作为 NoPe-NeRF 的创新点之一,有点怪异。相邻帧约束的优化会让人直觉上认可这一点,可惜文中并没有给出实验证据。(深度学习怎么解释都说得通,但真得 Show 一 Show 实验数据)
而且和学长讨论时还有一个问题,NoPe-NeRF 似乎并不能处理无序输入序列,看来 NoPe-NeRF 对数据的要求仍然不低。
综上,个人觉得除了在低纹理下有明显优点以外,其余在实验中显示相比 NeRF 并无明显提升。其中提及最多的 “能处理大相机运动” 为什么完全没有实验佐证?